février 2023
Nous sommes quatre étudiants alternants en dernière année à Polytech Nice Sophia, dans la spécialité Informatique et la mineure Architecture Logicielle :
La programmation orientée objet (POO) est un paradigme de programmation qui permet de modéliser des concepts du monde réel sous forme de classes et d’objets. Elle est devenue l’un des standards de l’industrie de développement de logiciels, car elle offre de nombreux avantages en termes de structure, de maintenance et de réutilisabilité du code.
Depuis sa création en 2011, Jupyter est devenue une plateforme populaire pour l’analyse de données et la science des données. Les notebooks Jupyter permettent aux utilisateurs de combiner du texte, du code et des visualisations dans un seul document interactif, ce qui les rend idéaux pour la documentation et la collaboration.
Cependant, il est important de se demander si la POO est utilisée dans les notebooks Jupyter et quel est son impact sur la qualité logicielle. En effet, la POO peut aider à structurer et à organiser le code de manière cohérente, ce qui peut améliorer la lisibilité et la maintenabilité du code. Cependant, il est également possible que la POO puisse rendre le code plus complexe et difficile à comprendre pour certains utilisateurs.
Il est donc intéressant de mener une étude pour évaluer l’utilisation de la POO dans les notebooks Jupyter et son impact sur la qualité logicielle. Cela pourrait être fait en examinant un échantillon de notebooks Jupyter populaire sur Github et en analysant leur utilisation de la POO, en interrogeant les développeurs sur leur utilisation de la POO dans leur travail quotidien avec Jupyter (ce qui n’est pas applicable au contexte de ce cours), et en utilisant des outils d’analyse de code pour évaluer la qualité du code dans les notebooks Jupyter qui utilisent la POO. Les résultats de cette étude pourraient être utiles pour les développeurs de logiciels qui utilisent Jupyter plus particulièrement les Data Scientistes.
La question générale que nous nous posons est : la programmation orientée objet est-elle utilisée dans les notebooks Jupyter et quel est son impact sur la qualité logicielle ?
Cette question nous intéresse car la POO est un paradigme de programmation largement utilisé dans l’industrie du développement logiciel, mais nous nous demandons si elle est également utilisée dans les notebooks Jupyter, qui sont principalement utilisés pour l’analyse de données et la science des données par les Data Scientistes. En outre, nous sommes intéressé par l’impact de l’utilisation de la POO sur la qualité logicielle dans les notebooks Jupyter, car la POO peut aider à structurer et à organiser le code de manière cohérente, mais peut également rendre le code plus complexe et difficile à comprendre voire maintenir.
De la question générale en découle plusieurs sous-questions qui nous permettent de mieux comprendre le sujet et d’aborder de manière plus précise et approfondie les différents aspects de la question :
Cette sous-question vise à déterminer l’utilisation de la POO dans les notebooks Jupyter en matière de pourcentage. Cela pourrait être fait en examinant un échantillon de notebooks Jupyter python trouvé sur Github et en comptant le nombre de notebooks qui utilisent la POO (grâce à un ensemble de règles/patterns que nous définirons et qui nous permettrons de reconnaitre l’usage de la POO dans ces notebooks)par rapport au nombre total de notebooks.
Cette sous-question vise à évaluer l’impact de l’utilisation de la POO sur la qualité logicielle dans les notebooks Jupyter python. Cela pourrait être fait en utilisant des outils d’analyse de code pour évaluer la qualité du code dans les notebooks Jupyter qui utilisent la POO, et en comparant cette qualité avec celle des notebooks qui n’utilisent pas la POO. On s’intéressera à Pylint qui est un outil de vérification de code python qui vise à améliorer la qualité du code en détectant les erreurs et en proposant des suggestions pour le rendre plus propre et plus maintenable.
Cette sous-question vise à évaluer l’impact de l’utilisation de la POO sur la popularité des notebooks Jupyter python. Cela pourrait être fait en utilisant le nombre d’étoiles et de forks sur Github.
Nous avons examiné des sources telles que des documents de recherche et des articles publiés sur des blogs qui traitent de l’utilisation de la programmation orientée objet (POO) par les scientifiques des données et de son utilisation dans les notebooks Jupyter de Python. Voici un résumé de la base sur laquelle nous avons fondé notre travail :
Object-Oriented Programming (OOP) in Python 3
Auteur : David Amos (programmer and mathematician passionate about exploring mathematics through code)
Type de document : Article
Résumé :
Cet article présente les bases de la POO en python et explique comment reconnaitre l’utilisation de la POO dans un code python. Il explique comment créer des classes et des objets, comment les utiliser pour stocker des données et comment les utiliser pour créer des fonctions et des méthodes. Il explique également comment représenter les grands concepts de la POO en python comme l’héritage, l’encapsulation et la polymorphisme. Grâce à cet article, nous avons appris les différents mots clés utilisés pour la POO en Python.
Nous avons :
class : utilisé pour définir une classe.
object : classe de base pour toutes les classes en Python, définit les méthodes de base pour les objets.
self : une référence à l’objet courant lors de l’exécution d’une méthode.
__init__() : une méthode spéciale appelée lors de la création d’un objet, utilisée pour initialiser les attributs de l’objet : le constructeur.
Afin de mener à bien notre projet de recherche sur l’utilisation de la POO dans les notebooks Jupyter Python, nous envisageons de rechercher sur GitHub les notebooks jupyter python. Pour faciliter notre recherche de notebooks, nous envisageons d’écrire des scripts Python qui vons nous nous permettre d’automatiser la recherche de fichiers d’extensions .ipynb sur GitHub grâce à son API. Les fichiers notebooks étant des fichiers scientifiques et pour avoir un grand volume de données, nous ne nous restreindrons pas à un domaine spécifique. Cela pour maximiser nos chances de trouver des notebooks utilisant la POO.
Les outils utiliser pour notre étude sont :
Pour vérifier notre hypothèse, nous avons collecté un échantillon représentatif de notebooks Jupyter publié par des data scientists en utilisant différentes sources telles que Github et les sites de partage de code. Au total, nous avons récupéré 262 repositories contenant des notebooks Jupyter.
Pour déterminer si chaque notebook utilise ou non la programmation orientée objet, nous avons utilisé un script automatisé que nous avons écrit. Cette méthode est basée sur l’analyse des fichiers sources pour identifier les caractéristiques de la POO. Pour identifier l’utilisation de la POO, nous avons utilisé les caractéristiques suivantes :
Cependant, cette étude présente des limites telles que le nombre limité d’échantillons disponibles et la restriction de collecte des notebooks par l’API Github.
Afin de vérifier notre hypothèse, nous avons décidé de faire une comparaison rigoureuse entre les notebooks Jupyter qui utilisent la POO et ceux qui ne l’utilisent pas. Pour atteindre cet objectif, nous avons sélectionné les notebooks qui utilisent la POO que nous avions identifiés lors de notre première étude, puis avons choisi un nombre égal de notebooks qui ne l’utilisent pas pour avoir des résultats équilibrés. Ensuite, nous avons évalué la qualité de ces notebooks en utilisant plusieurs critères tels que :
Le résultat final qui nous permettra de vérifier notre hypothèse sera la comparaison des résultats pour déterminer s’il existait une différence significative entre les deux groupes de notebooks.
Afin de vérifier notre hypothèse concernant la qualité des codes dans les notebooks Jupyter, nous avons décidé d’utiliser l’outil populaire SonarQube pour l’analyse. Nous avons utilisé SonarQube pour mesurer la qualité du code présent dans les notebooks Jupyter en suivant les critères définis précédemment. Cependant, les résultats obtenus ont indiqué un score de zéro sur chaque critère, ce qui signifiait qu’il n’y avait aucun problème. Cela peut être dû au fait que SonarQube n’a pas été conçu pour analyser les codes scientifiques, et que les codes que nous avons analysés étaient écrits par des data scientists. Les critères pour évaluer la qualité du code peuvent différer de ceux utilisés dans d’autres projets. Pour remédier à ce problème, nous avons décidé de changer d’outil et de recommencer l’analyse en utilisant un outil différent appelé Pylint.
Après un premier essai qui n’a pas donné les résultats escomptés, nous avons décidé d’utiliser Pylint pour mesurer la qualité du code. Pylint est un outil qui permet d’évaluer les notebooks en analysant différents critères tels que le nombre de lignes de code, de commentaires, de lignes vides, de fonctions et de méthodes, d’expressions complexes, de variables et de classes. Il peut également signaler des erreurs et des problèmes potentiels dans le code.
Pour mener à bien cette tâche, nous avons effectué les étapes suivantes :
Tout ceci a été automatisé grâce à un script .bash fourni avec l’outil.
Afin de vérifier l’hypothèse, nous allons utiliser les mêmes référentiels que ceux utilisés pour l’étude de l’hypothèse 2. Nous avons toujours deux groupes de référentiels : ceux qui utilisent la programmation orientée objet et ceux qui n’utilisent pas la programmation orientée objet.
Nous utilisons l’API Github pour obtenir:
Malheureusement, nous n’avons pas accès au nombre de clones, ce qui aurait été une information intéressante à inclure.
L’hypothèse sera considérée comme vérifiée si le nombre d’étoiles sur Github des notebooks utilisant la POO sont significativement supérieurs à ceux des notebooks n’utilisant pas la POO.
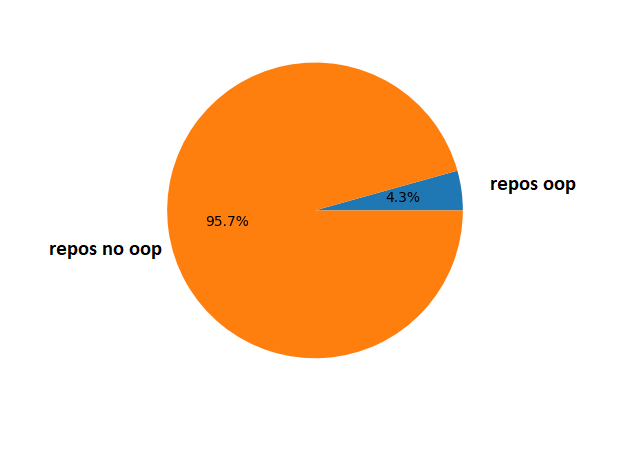
D’après les données représentées sur le graphique, il est clair que l’utilisation de la Programmation Orientée Objet (POO) est très peu répandue chez les utilisateurs de notebooks. Seulement 4,3% des utilisateurs de notebooks utilisent la POO, tandis que 95,7% n’en font pas usage. Cependant, il est important de prendre en compte les limites de l’étude, notamment le nombre restreint d’échantillons disponibles et la restriction de collecte des notebooks via l’Api Github.
L’hypothèse 1 soutenait que “l’utilisation de la POO est largement adoptée par les data scientistes pour améliorer la qualité de leurs notebooks”. Cependant, en considérant les données obtenues avec nos limites, nous pouvons conclure que l’utilisation de la POO est très peu fréquente dans les notebooks Jupyter. Par conséquent, nous rejetons l’hypothèse 1.
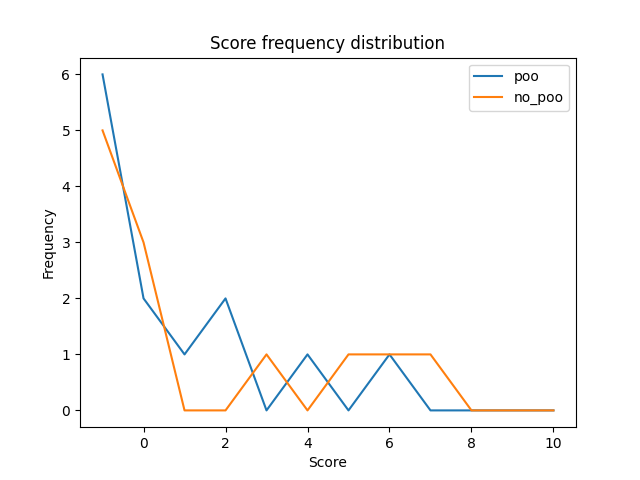
Au cours de notre étude, nous avons observé que les notebooks qui utilisent la programmation orientée objet (POO) et ceux qui ne l’utilisent pas, ont tous les deux une quantité presque identique de notebooks qui ne peuvent pas être compilés par Pylint. Le score “-1” étant attribué aux notebooks non compilés par Pylint. Pour les notebooks pour lesquels Pylint a pu évaluer leur qualité (score >= 0), nous n’avons pas constaté de grandes différences entre les deux groupes de notebooks. Cela montre que l’utilisation de la POO n’augmente pas de manière significative la qualité logicielle des notebooks. Ce fait peut également être justifié par le fait que le notebook ayant le score le plus élevé dans notre jeu de données n’utilise pas la POO.
En conclusion, nous pouvons affirmer que l’application de bonnes pratiques de développement, y compris la POO, peut contribuer à améliorer la qualité logicielle des notebooks. Cependant, il n’est pas nécessaire d’utiliser la POO pour créer des notebooks de haute qualité. Cette hypothèse est donc validée.
Notez cependant que cette étude est limitée par le nombre restreint de notebooks utilisés pour l’étude.
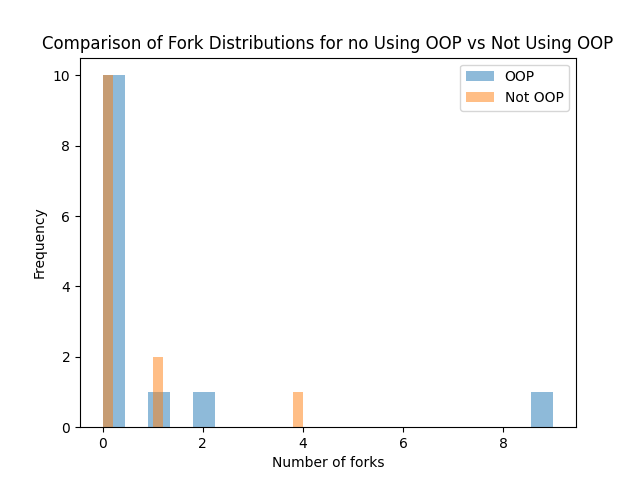
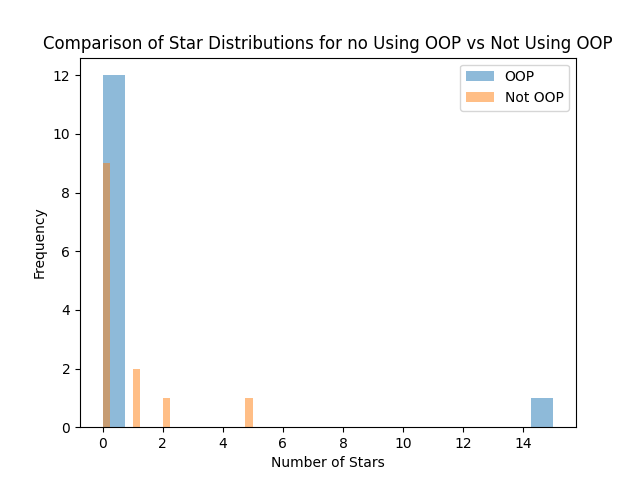
Nous constatons sur le graphique 1 que les notebooks sur Github qui utilisent la programmation orientée objet (POO) ont un nombre de forks significativement plus élevé par rapport à ceux qui n’utilisent pas la POO. Cette observation suggère que les notebooks qui utilisent la POO sont considérés plus utiles et précieux pour la communauté, car les forks sont souvent créés pour partager, améliorer et collaborer sur le code source original. De plus, la POO offre une modularité, une encapsulation et un héritage solides qui peuvent faciliter la maintenance et le développement du code, ce qui peut également expliquer la popularité accrue des notebooks utilisant la POO. Enfin, ces résultats montrent l’importance d’utiliser la POO pour écrire du code clair, organisé et facile à travailler pour les développeurs de la communauté.
En ce qui concerne le nombre d’étoiles sur Github (graphique 2), il semble que les notebooks sans POO ont en effet plus d’étoiles que ceux qui utilisent explicitement la POO.
En conclusion, le nombre d’étoiles et de forks sur Github nous indique que les notebooks utilisant la POO sont plus populaires que ceux n’utilisant pas la POO. Cette hypothèse est donc validée.
Notez toujours que cette étude est limitée par le nombre restreint de notebooks utilisés pour l’étude.
Durant cette étude, nous avons rencontré plusieurs limitations qui ont affecté notre capacité à acquérir les données souhaitées.
De nombreux data scientistes utilisent la POO dans leurs notebooks Jupyter sans même le savoir. Cela est dû au fait que de nombreuses bibliothèques populaires utilisées dans le domaine des sciences des données, telles que scikit-learn, TensorFlow et autres, sont construites en utilisant la POO. En utilisant ces bibliothèques, les data scientistes manipulent souvent des objets tels que des modèles de machine learning, des jeux de données, etc. qui sont des instances de classes définies par ces bibliothèques. Même si ces data scientistes n’ont pas nécessairement conscience de la POO, ils en bénéficient tout de même en bénéficiant de la modularité, de l’encapsulation et de l’héritage que cette technique de programmation offre. Nous l’avons constaté suite à une étude menée sur les libraires les plus populaires utilisées par les scientistes.
Exemple 1 : Création d’un réseau de neurone avec la bibliothèque TensorFlow
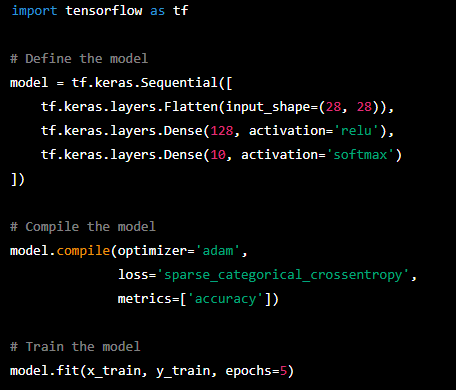
Dans ce code, nous utilisons la classe Sequential pour définir notre modèle de réseau de neurones en lui fournissant les différents paramètres par argument. Les méthodes compile et fit sont appelés sur la référence de l’objet model créé. Celles-ci font donc partie de la classe Sequential; une caractérisation de l’encapsulation.
Exemple 2 : Création d’un model de regression linéaire avec la bibliothèque Scikit learn
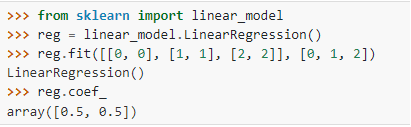
Dans ce code, nous utilisons la classe LinearRegression pour définir notre modèle de régression linéaire en lui fournissant les differents paramètres par argument. La méthode fit est appelée sur la référence de l’objet model créé. Celle-ci fait donc partie de la classe LinearRegression; une caractérisation de l’encapsulation. L’attribut req_ fait également partie de la classe LinearRegression
Pour vérifier l’utilisation de la POO dans les fichiers notebooks, nous avons effectué une recherche de mots clés (décrits dans la section III. Collecte d’informations) en premier lieu en parcourant manuellement les fichiers, puis nous avons automatisé ce processus en utilisant des expressions régulières (regex). Cela nous a permis d’automatiser la tâche et d’augmenter notre productivité.
Nous avons mis en place un outil (en réalité des scripts python automatisés) qui nous ont permis de récupérer des notebooks Jupyter python sur Github; de transformer ces notebooks en fichiers python (pour mieux les traiter); de déterminer la présence de l’utilisation de la POO dans ces derniers; d’analyser la qualité du code dans ces notebooks et de visualiser les résultats obtenus grâce à des graphiques.
un README.md contenant les instructions d’utilisation de l’outil est disponible dans le répertoire /code/ du rendu.
En conclusion, bien que seulement 4.3% des data scientistes utilisent explicitement la programmation orientée objet (POO) dans les notebooks Jupyter Python, ils en bénéficient en utilisant les nombreuses librairies de data science qui recourt à la POO. Cependant, l’utilisation de la POO n’augmente pas de manière significative la qualité du code dans les notebooks jupyter. Quant à la popularité des notebooks, il semble que ceux utilisant la POO de manière explicite sont plus populaires auprès de la communauté que ceux n’utilisant pas la POO.
Comme perspectives futures, nous pensons étendre et approfondir notre recherche en étudiant l’évolution de l’utilisation de la POO dans le notebooks jupyter python. Nous prévoyons également d’élargir notre étude aux notebooks jupyter utilisant le langage R.
![]()